Auteurs principaux: Emilia Diaconescu (CCSC/ECCC) et Paul Kushner (Université de Toronto)
Le présent rapport tient principalement compte des sources de données suivantes pour le Nord canadien : les données provenant des stations (aperçu à la section 2.1.1), les observations sur grille (section 2.1.2), les réanalyses (section 2.1.3) et les ensembles de données de télédétection. Ces sources représentent les façons distinctives dont les données climatiques sont fournies, soit à un point précis (p. ex., données d’une station, mesures d’un site) ou sur une grille (p. ex., réanalyses, observations remaillées, ensembles de données de télédétection sur grille). Les données ponctuelles transmettent de l’information propre à un endroit donné où les mesures sont prises, tandis que les données sur grille fournissent des informations représentatives des valeurs moyennes ou typiques de la zone ou du volume couvert par la cellule de la grille. En d’autres mots, les variables d’un produit sur grille doivent généralement être interprétées comme des valeurs moyennes de la cellule de la grille et non comme des mesures ponctuelles. Pour relier plus précisément les valeurs sur grille aux mesures locales, il faut utiliser des méthodes de mis à l’échelle qui seront mentionnées en lien avec des applications précises.
2.1.1 Données des stations
Les stations météorologiques et les sites sur le terrain fournissent les mesures les plus fiables et les plus précises de plusieurs des variables prises en compte dans le présent rapport, comme la température, les précipitations, l’humidité, le vent, l’épaisseur de la neige, l’équivalent en eau de la neige et le débit des rivières. Cependant, l’infrastructure et l’entretien des stations sont coûteux et nécessitent une expertise technique approfondie pour en assurer l’entretien ou, dans le cas des sites sur le terrain, fournir une couverture propre au projet. Cela limite le nombre et la répartition des stations de mesure dans le Nord canadien par rapport au Sud canadien. Par exemple, les stations météorologiques dans le Nord canadien sont situées sur la côte ou dans les vallées, et il y a un nombre limité de stations dans les régions terrestres intérieures (voir la figure 2.1 qui montre l’emplacement des stations météorologiques au Canada en septembre 2016, et la section 3.1). Lorsqu’on utilise des données de stations météorologiques sur plusieurs décennies, l’analyse du climat doit tenir compte des valeurs manquantes et des enregistrements qui couvrent différentes périodes. Les changements d’instrumentation, d’emplacement et d’échantillonnage doivent être pris en compte afin d’éviter l’apparition de variations trompeuses non liées au climat. Par exemple, en 1961, il y a eu une modification du temps d’observation aux stations principales, ce qui a eu une incidence sur les relevés quotidiens des températures minimales.
L’Jeu de données climatiques canadiennes ajustées et homogénéisées (DCCAH, Mekis et Hogg, 1999; Mekis et Vincent, 2011; Vincent et coll., 2012, 2020) d’ECCC résout certains de ces problèmes pour plusieurs variables climatiques ciblées dans le présent rapport. Dans ce produit, les observations quotidiennes ou mensuelles des sites avoisinants sont souvent fusionnées pour créer une série chronologique plus longue, et les enregistrements ont été testés pour des variations artificielles (qui pourraient être causées par des changements d’emplacement des stations) et homogénéisés (c.-à-d. ajustés pour tenir compte des variations artificielles). À l’heure actuelle, ce groupe recommande que les DCCAH soient utilisées comme le meilleur Jeu de données pour analyser l’évolution du climat local sur une longue période au Canada. Cela reflète les pratiques actuelles, puisque les DCCAH sont souvent utilisées pour valider d’autres ensembles de données sur grille et modèles. Des descriptions détaillées des enregistrements des DCCAH sont fournies dans les annexes (c.‑à‑d. les annexes portant sur la température, les précipitations et le vent). À noter que le nombre d’emplacements ayant des données DCCAH disponibles est généralement peu élevé dans le Nord canadien (encore moins d’emplacements que pour l’ensemble des stations du Service météorologique du Canada (SMC)).
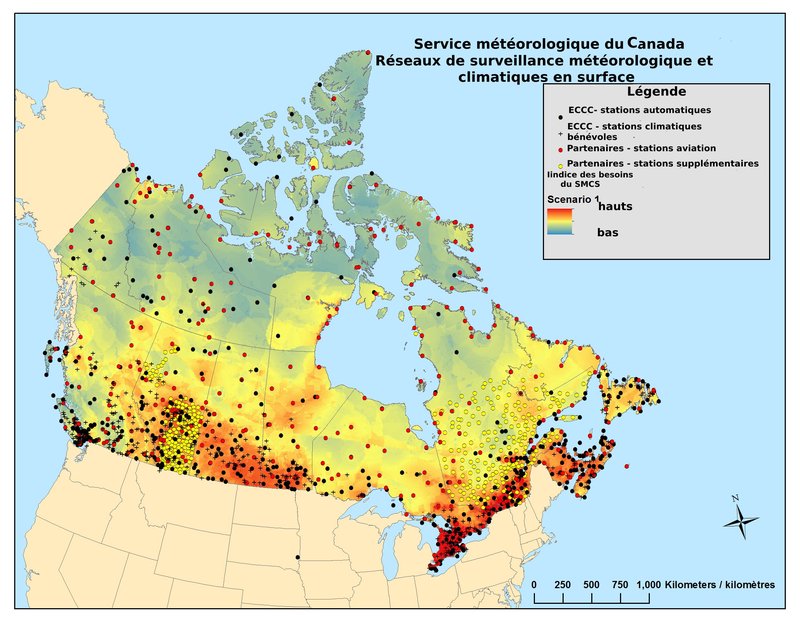
Figure 2.1. Stations météorologiques de surface au Canada, pour septembre 2016, avec une carte de l’indice des besoins en arrière-plan. Pour plus de détails sur l’évolution du réseau des stations, voir Mekis et coll., 2018. (Source : Mekis et coll., 2018)
2.1.2 Données des stations sur grille
Les données ponctuelles des stations peuvent être transformées en produits sur grille à l’aide d’une gamme de méthodes d’interpolation mathématiques et statistiques. Ces méthodes vont des plus simples, comme la pondération inverse à la distance, l’analyse par surfaces de tendance, les fonctions splines (utilisées dans ANUSPLIN et WorldClim2) et les polygones de Thiessen, aux plus complexes, comme les modèles de régression ou de krieging (utilisés dans PNWNAMET). Bien qu’ils aient une résolution spatiale nominale aussi fine que 1 km (p. ex., Daymet, WorldClim2), la pertinence de ces ensembles de données dans le Nord canadien n’a généralement pas été bien ananlysée. Le principal facteur qui influence la capacité des plusieurs méthodes d’interpolation est la densité du réseau de stations; la complexité topographique, et la façon dont elle est prise en compte dans le modèle, constitue un deuxième facteur important. (Hofstra et coll., 2008). Seuls certains des ensembles de données sur grille tiennent compte des effets de l’élévation (p. ex., ANUSPLIN, PNWNAMET, WorldClim2, Daymet). À mesure que la distance moyenne entre les stations qui sont maillées devient supérieure à 100 km, l’efficacité de toutes les méthodes d’interpolation se dégrade. De tels effets sont prononcés dans l’analyse des extrêmes de température et de précipitation, comme cela a été démontré pour les données des stations européennes (Hofstra et coll., 2010), pour lesquelles les valeurs quotidiennes interpolées sont systématiquement réduites par rapport à la moyenne « réelle » de la zone. Cela a une forte incidence sur les variables climatiques ayant une variance spatiale relativement élevée, comme les précipitations par rapport à la température, mais peut aussi avoir une incidence sur des variables comme la température en surface dans les régions montagneuses à forte variabilité topographique. De grandes parties du Nord canadien, ayant un relief important dans l’Ouest canadien et une faible répartition des stations à l’intérieur des terres, se trouvent dans cette situation (figure 2.1). La variabilité spatiale et temporelle est plus grande dans les régions à relief élevé et à pas de temps quotidiens, mais cet effet diminue pour les moyennes mensuelles et annuelles.
Therefore, despite their past use, the use of datasets obtained with gridding methods for regions of the Canadian North that feature a sparse network of stations should be approached cautiously. Local conditions should be considered when selecting the dataset obtained with a gridding method. For example, applications with a good coverage of stations over a small watershed could consider the use of a gridded dataset. If the region has important topographic variations, a method that incorporates elevation information should be used (see Section 3.1 for further discussion on these points related to temperature). For regions with a small number of stations, hybrid products that make use of assimilation of observations and model output (e.g., RDRSv2) could be a good alternative to gridded observations.
En raison de la demande de produits à plus haute résolution dans de nombreuses applications, le présent rapport se concentre généralement sur des versions récentes des ensembles de données qui sont fournies à une résolution spatiale nominale supérieure à environ 60 km/0,5°, couvrant le Nord canadien ou certaines parties du Nord canadien. Dans le but d’utiliser ces données pour des applications climatiques, nous n’avons conservé que des ensembles de données couvrant une période d’au moins dix ans. Néanmoins, il faut garder à l’esprit les préoccupations mentionnées ci-dessus concernant l’utilisation de données interpolées provenant de réseaux épars.
2.1.3 Réanalyses et ensembles de données basés sur des réanalyses
Les réanalyses constituent un complément précieux aux données des observations sur grille obtenués uniquement avec des methodes d’interpolation. Les réanalyses sont produites en assimilant les données d’observation (p. ex., les données de rayonnement disponibles des satellites, les observations en surface, y compris les stations terrestres et les observations maritimes, les données des aéronefs, des radiosondage-radiovent et des profileurs) en modèles de prévisions météorologiques numériques sur de longues périodes historiques (voir Cullather et coll., 2016 pour une description complète). Les réanalyses offrent un grand nombre de variables météorologiques et de la surface terrestre qui préservent les relations physiques entre elles et couvrent une longue période et des échelles spatiales allant de l’échelle régionale à l’échelle mondiale de manière uniforme et cohérente. Disponibles à une résolution de plus en plus haute, elles représentent une source précieuse de données pour les modèles des impacts et les modèles climatiques qui nécessitent l’entrée de plusieurs variables avec la cohérence physique préservée. Les spécialistes doivent porter une attention particulière à la résolution horizontale de chaque produit de réanalyse (p. ex., 0,25 degré à 1 degré) et reconnaître les limites de son échantillonnage temporel (p. ex., 1 h, 3 h, 6 h, quotidien).
La qualité des observations, du processus d’assimilation et du modèle numérique sous-jacent détermine la précision du produit de réanalyse. Lorsque les observations sont relativement rares, les résultats de la réanalyse sont davantage influencés par le modèle de prévision. Comme il a été mentionné précédemment, le Nord canadien dispose d’un nombre limité d’observations sur site. De plus, les capteurs satellitaires ont de la difficulté à profiler la basse atmosphère sur des surfaces recouvertes de neige et de glace, et les satellites géostationnaires ne couvrent pas les hautes latitudes (Cullather et coll., 2016). Par conséquent, les observations imposent moins de contraintes aux réanalyses dans le Nord canadien que dans le Sud canadien. Il convient également de noter que si, à un moment donné, un nouveau type d’observation est introduit dans le schéma d’assimilation des données (p. ex., nouvelles données satellitaires), le résultat sera par la suite plus contraint par les observations que dans la période précédente. Cela peut produire une variabilité ou des tendances artificielles pour variables estimées.
En tenant compte de leurs limites connues, les réanalyses, en particulier celles accompagnées d’une quantification de l’incertitude des estimations de l’état, restent les meilleures et les plus cohérentes estimations en continu de l’état de l’atmosphère et, dans certains cas, les seules estimations disponibles (Cullather et coll., 2016). Par exemple, les prévisions saisonnières pour l’Arctique sont actuellement vérifiées en comparant les estimations du modèle avec les données de réanalyse pour de nombreuses variables, y compris la température à 2 m (voir les présentations sur l’Arctic Regional Climate Centre [arctic-rcc.org][en anglais seulement]). Dans le présent rapport, notre discussion sur les produits de réanalyse porte sur quatre importants centres qui produisent des réanalyses atmosphériques globales, à savoir le Centre européen pour les prévisions météorologiques à moyen terme (connu sous son acronyme anglais, ECMWF), la National Aeronautics and Space Administration (NASA), le National Centers for Environmental Prediction (NCEP) et la Japan Meteorological Agency (JMA). Nous nous reporterons fréquemment aux produits de réanalyse ERA5 de l’ECMWF, MERRA2 de la NASA, CFSR du NCEP et JRA-55 de la JMA (voir la Liste des acronymes pour leurs définitions).
La nécessité d’augmenter la résolution spatiale des réanalyses et d’optimiser la performance dans des régions précises a entraîné l’introduction de réanalyses régionales et de ré-prévisions à l’aide de modèles de prévision numérique à surface limitée et à haute résolution (p. ex., le NARR du NCEP, l’ASRv2 élaboré par le Byrd Polar Research Center et le RDRSv2 d’ECCC). Ces approches simulent l’état atmosphère et/ou du sol à une résolution plus haute que les réanalyses globales, et l’assimilation continue des observations limite la tendance du modèle à dériver et limite ainsi les erreurs typiques aux méthodes de mise à l’échelle dynamique. Des trois produits régionaux qui couvrent le Nord canadien, le NARR a une résolution spatiale plus basse que la réanalyse globale ERA5 (32 km comparativement à environ 28 km), tandis que l’ASRv2 (15 km) et du RDRSv2 (10 km) sont de nouveaux produits qui couvrent seulement la période récente.
De plus, les réanalyses atmosphériques globales peuvent être utilisées pour forcer des modèles avancés de la surface terrestre à une résolution plus haute (p. ex., MERRA-Land et ERA5-Land). Les observations dans les modèles de surface terrestre ont une influence indirecte par le forçage atmosphérique utilisé pour exécuter le modèle terrestre; cette influence indirecte peut entraîner une certaine dérive de la solution du modèle. D’autre part, la cohérence interne des lois physiques et une résolution plus haute qui incorpore avec précision l’influence du terrain, sont des forces de cette approche. ERA5-Land, par exemple, fournit une température à 2 m à une résolution spatiale de 10 km, tandis que la variable correspondante d’ERA5 est d’environ 28 km.
D’autres approches pour obtenir des données à haute résolution consistent dans la mis à l’échelle des réanalyses atmosphériques globales avec ou sans correction de biais (p. ex., AgMERRA, AgCFSR, AgERA, GMFD, CRU JRA et S14FD). AgMERRA (environ 28 km; basé sur la réanalyse MERRA), AgCFSR (environ 28 km; basé sur la réanalyse CFSR) et AgERA (10 km; basé sur la réanalyse ERA) ont été élaborés pour être utilisés comme données d’entrée pour les études agricoles et agroécologiques. Par conséquent, les données subhoraires de plusieurs données météorologiques de surface ont été agrégées à un pas de temps quotidien (pour la température de l’air, les données quotidiennes sont fournies pour la température quotidienne moyenne, minimale et maximale). Les réanalyses GMFD (environ 28 km; basé sur la réanalyse NCEP/NCAR), CRU JRA (environ 56 km; basé sur la JRA-55) et S14FD (environ 56 km; basé sur la JRA-55) ont été élaborées pour servir d’ensembles de données de forçage pour différents modèles d’impact. Tous ces produits utilisent des méthodes d’interpolation comme approche de mis à l’échelle pour obtenir l’augmentation de la résolution nominale. Le chapitre 3 fournit des renseignements sur les variables particulières disponibles à partir de toutes ces réanalyses.
Les spécialistes doivent savoir quelles données sont assimilées dans une réanalyse donnée; bien que cela soit documenté dans les produits compilés ici, l’identification des sources de données utilisées dans l’assimilation demeure un défi pour les utilisateurs nouveaux et même expérimentés. Un point général est que même si les réanalyses assimilent de nombreuses observations, les observations les plus nombreuses proviennent de données satellitaires, qui ont commencé véritablement à être recueillies au début des années 1970 et sont devenues une partie régulière de l’assimilation opérationnelle dès le début de l’ère des satellites, en 1979. Plus précisément, les réanalyses MERRA, CFSR et NCEP n’assimilent pas les mesures de la température en surface et des précipitations aux stations. Il convient également de noter que les réanalyses ERA5, NARR et RDRSv2 assimilent à certains égards la température en surface des stations. La réanalyse JRA-55 assimile indirectement certaines mesures de la température en surface, ainsi que des hyperfréquences passives pour la couverture de neige, mais pas les précipitations (Kobayashi et coll., 2015). AgMERRA, AgCFSR, GMFD, CRU JRA et S14FD transforment des variables de surface des réanalyses atmosphériques globales à une résolution plus haute ou les corrigent avec les données en surface des stations. Ces corrections et le processus de mis à l’échelle peuvent avoir une incidence sur les relations physiques entre les variables de chaque Jeu de données. Par conséquent, pour le Nord canadien, les corrections ne garantissent pas a priori un meilleur Jeu de données que ceux des réanalyses globales « parentes » ou des produits régionaux ayant une résolution spatiale semblable ou plus haute (p. ex., ERA5, ASRv2, RDRSv2, ERA5-Land), qui, comme il a été mentionné précédemment, maintiennent la cohérence interne correspondante à la résolution du modèle « parent ». Les ensembles de données AgMERRA, AgCFSR et GMFD n’ont pas été mis à jour depuis 2014 et il n’est pas prévu de les maintenir. AgERA5 est un nouveau produit basé sur ERA5. AgERA5 ne corrige pas les biais d'ERA5, ne fait qu’agréger les pas de temps quotidiens au fuseau horaire local et corrige les champs pour une topographie plus fine à l’aide d’équations de régression caractéristiques au modèle atmosphérique à haute résolution (HRES) opérationnel de l’ECMWF, qui à une résolution de 0,1°.
Dans la la littérature approuvée par les pairs, la comparaison des produits de réanalyse avec les produits des stations sur grille (section 2.1.2) est couramment effectuée, mais elle est sujette à des erreurs de représentation (Keller et Wahl, 2021; Cullather et coll., 2016), puisque la moyenne des données sur grille dépend fortement de la densité des observations. La comparaison des données de réanalyse avec les mesures aux stations sur place (section 2.1.1) est également sujette à des erreurs de représentation, en particulier dans les régions où la topographie ou l’hétérogénéité de surface sont complexes (Keller et Wahl, 2021). Les comparaisons de ce genre doivent être effectuées à l’aide de données indépendantes et validées (observations qui ne sont pas intégrées ou assimilées dans la réanalyse), ce qui est parfois difficile à trouver. La validation par rapport aux données qui sont assimilées aura tendance à donner de bons résultats à ces endroits précis, mais ne garantit pas de bons résultats loin de ces endroits.
Dans l’ensemble, les utilisateurs doivent garder à l’esprit les points clés suivants liés à l’utilisation des réanalyses :
- Il faut faire preuve de prudence dans l’utilisation des réanalyses au Nord canadien et, en particulier, il faut s’assurer de bien caractériser la façon dont différentes réanalyses représentent les variables d’intérêt à proximité des stations ou des emplacements de mesure sur le terrain, aussi rares soient-elles. On peut s’attendre à ce que les réanalyses soient plus semblables aux observations aux stations à ces endroits, mais divergent dans les régions sans station.
- Il faut faire attention lorsqu’on utilise des réanalyses pour définir les tendances ou la variabilité sur une longue période, car les changements dans les quantités et les types de données d’observation qui sont assimilées par celles-ci peuvent produire des tendances artificielles ou introduire de la variabilité artificielle dans la série chronologique de l’Jeu de données.
- La conclusion générale de Przybylak et Wyszyński (2020) (voir aussi Serreze et Barry, 2014) doit également être prise en compte : « En raison des écarts dans les réanalyses, il est nécessaire de prendre en considération les moyennes de données de multiples réanalyse pour analyser correctement la moyenne de l’état du système climatique de l’Arctique [traduction libre] ».